
Misc - Whitespace - Solver
A block is made of two symbols from a 5x3 font. We infer that from the fact that the longest line is made of 6 "#".
Since we know the flag starts with L3AK, we can test it out :
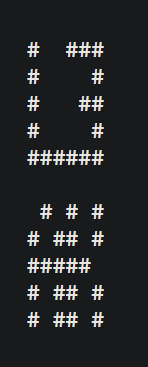
If we remove the spaces, it matches the first two blocks of the challenge. b1 = L3 and b2 = AK
We used the following website to build our own alphabet in code :
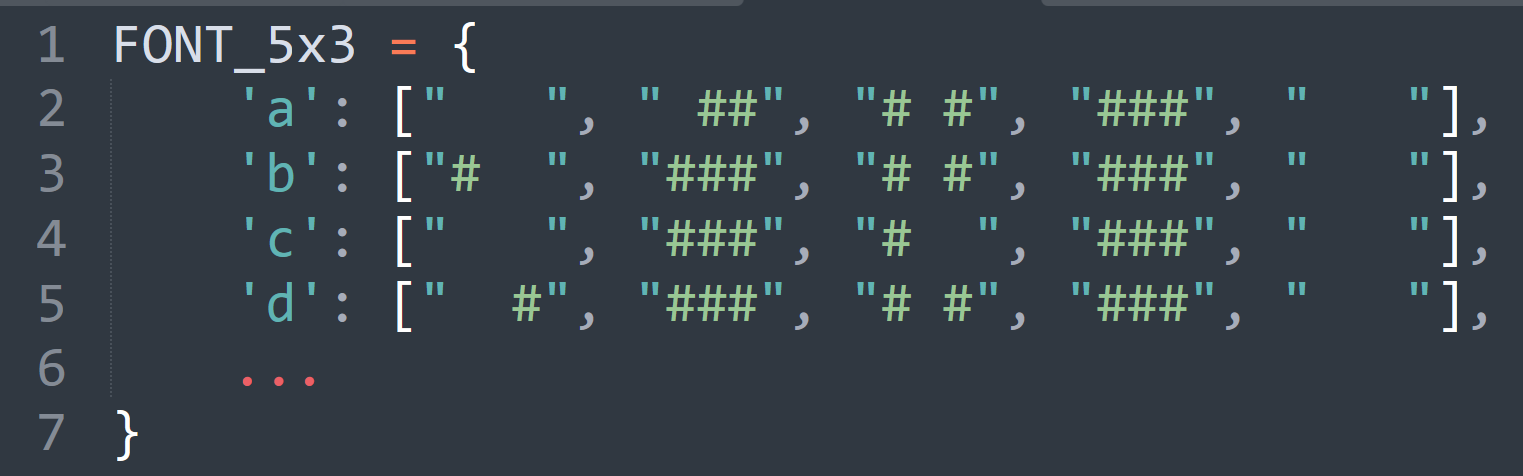
The alphabet contains the following symbols : [a-zA-z0-9] and "{ ? ! @ }"
Each block can be made using at least one pair of symbols. There might be more than one pair, we don't know.
Let's build a list of possible combinations for each block.
The script attached to this document computes all the possibilities using our newly made alphabet. Once it's finished, we can see the results :
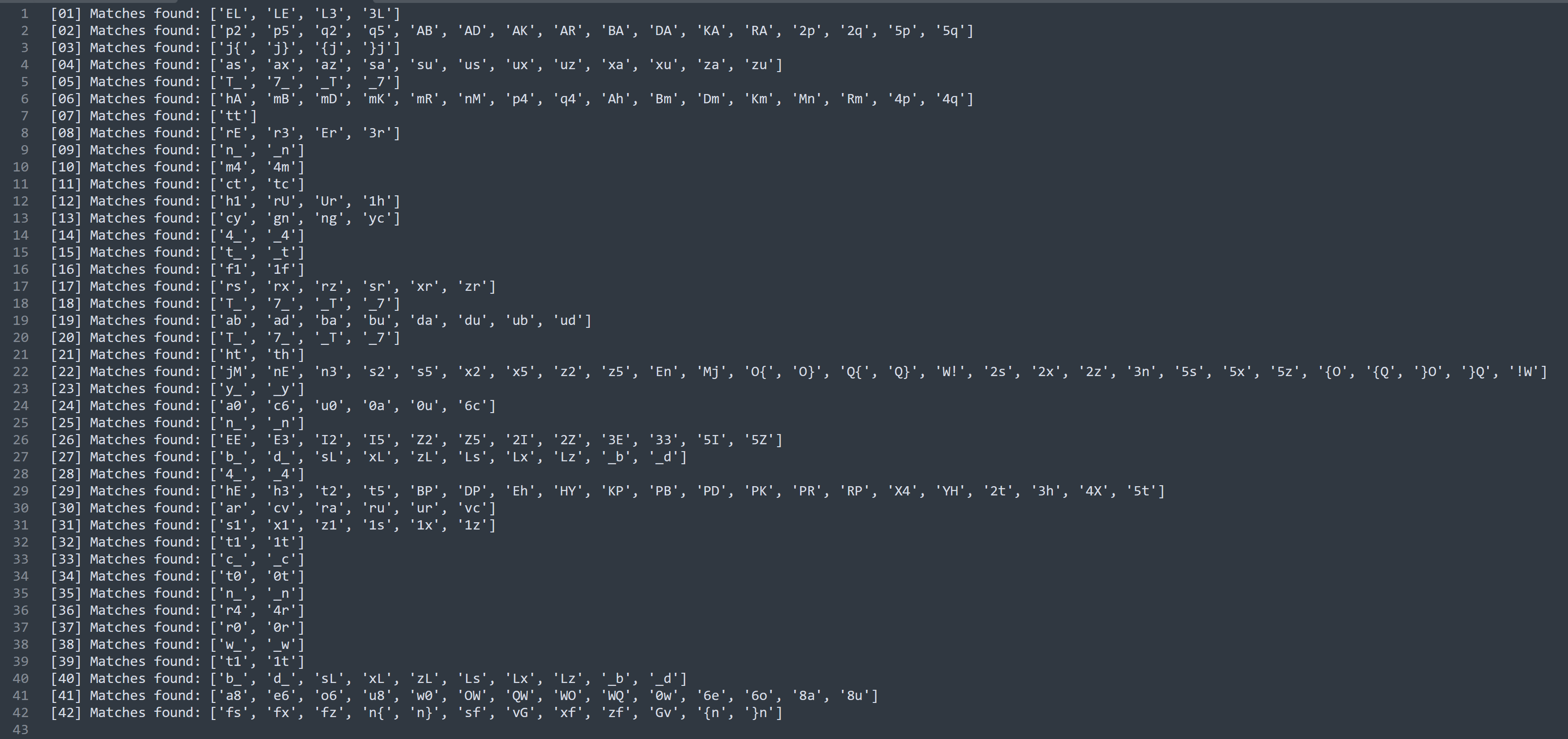
We have 42 blocks which aligned perfectly with our challenge. We know we have processed all the blocks without any issues.
As we can see, the combinations for the first block are : [ 'EL', 'LE', 'L3', '3L' ]
We already know that it's 'L3' but we can also see '3L' which means we need to take into account that reversed pairs output the same result regardless of the order.
We can apply some filtering on the combinations. For example, we can remove any combination containing '{' and '}' and are not attached to the block n°3 or to the block n°42. We can't have these symbols 'inside' the flag.
There might be some ambiguity left at the end. Although, the flag is fairly simple to find once we have the combinations reduced.
The script attached to this document computes the final md5 hash to confirm we have the correct flag.
import hashlib
from itertools import product
# 5x3 font
FONT_5x3 = {
'a': [" ", " ##", "# #", "###", " "],
'b': ["# ", "###", "# #", "###", " "],
'c': [" ", "###", "# ", "###", " "],
'd': [" #", "###", "# #", "###", " "],
'e': [" ", "###", "## ", "###", " "],
'f': [" ##", " # ", "###", " # ", "## "],
'g': [" ", "###", "# #", " ##", "###"],
'h': ["# ", "###", "# #", "# #", " "],
'i': [" # ", " ", " # ", " ##", " "],
'j': [" #", " ", " #", " #", " # "],
'k': ["# ", "# #", "## ", "# #", " "],
'l': [" # ", " # ", " # ", " ##", " "],
'm': [" ", "###", "###", "# #", " "],
'n': [" ", "## ", "# #", "# #", " "],
'o': [" ", "###", "# #", "###", " "],
'p': [" ", "###", "# #", "###", "# "],
'q': [" ", "###", "# #", "###", " #"],
'r': [" ", "###", "# ", "# ", " "],
's': [" ", " ##", " # ", "## ", " "],
't': [" # ", "###", " # ", " ##", " "],
'u': [" ", "# #", "# #", "###", " "],
'v': [" ", "# #", "# #", " # ", " "],
'w': [" ", "# #", "###", "###", " "],
'x': [" ", "# #", " # ", "# #", " "],
'y': [" ", "# #", "###", " #", "###"],
'z': [" ", "## ", " # ", " ##", " "],
'A': [" # ", "# #", "###", "# #", "# #"],
'B': ["## ", "# #", "## ", "# #", "## "],
'C': [" ##", "# ", "# ", "# ", " ##"],
'D': ["## ", "# #", "# #", "# #", "## "],
'E': ["###", "# ", "## ", "# ", "###"],
'F': ["###", "# ", "## ", "# ", "# "],
'G': [" ##", "# ", "# #", "# #", " ##"],
'H': ["# #", "# #", "###", "# #", "# #"],
'I': ["###", " # ", " # ", " # ", "###"],
'J': [" ##", " #", " #", "# #", " # "],
'K': ["# #", "# #", "## ", "# #", "# #"],
'L': ["# ", "# ", "# ", "# ", "###"],
'M': ["# #", "###", "###", "# #", "# #"],
'N': ["###", "# #", "# #", "# #", "# #"],
'O': [" # ", "# #", "# #", "# #", " # "],
'P': ["## ", "# #", "## ", "# ", "# "],
'Q': [" # ", "# #", "# #", " ##", " #"],
'R': ["## ", "# #", "## ", "# #", "# #"],
'S': [" ##", "# ", " # ", " #", "## "],
'T': ["###", " # ", " # ", " # ", " # "],
'U': ["# #", "# #", "# #", "# #", "###"],
'V': ["# #", "# #", "# #", "# #", " # "],
'W': ["# #", "# #", "###", "###", "# #"],
'X': ["# #", "# #", " # ", "# #", "# #"],
'Y': ["# #", "# #", " # ", " # ", " # "],
'Z': ["###", " #", " # ", "# ", "###"],
'0': ["###", "# #", "# #", "# #", "###"],
'1': [" # ", "## ", " # ", " # ", "###"],
'2': ["###", " #", "###", "# ", "###"],
'3': ["###", " #", " ##", " #", "###"],
'4': ["# #", "# #", "###", " #", " #"],
'5': ["###", "# ", "###", " #", "###"],
'6': ["###", "# ", "###", "# #", "###"],
'7': ["###", " #", " #", " #", " #"],
'8': ["###", "# #", "###", "# #", "###"],
'9': ["###", "# #", "###", " #", "###"],
'{': [" ##", " # ", "## ", " # ", " ##"],
'}': ["## ", " # ", " ##", " # ", "## "],
'_': [" ", " ", " ", " ", "###"],
'?': ["###", " #", " ##", " ", " # "],
'!': [" # ", " # ", " # ", " ", " # "],
'@': ["###", "# #", "# ", "###", " "],
# '+': [" ", " # ", "###", " # ", " "],
# '-': [" ", " ", "###", " ", " "]
}
def strip_spaces(line):
return line.replace(" ", "")
def find_all_two_char_matches(target, font):
target_stripped = [strip_spaces(line) for line in target]
matches = []
for ch1, ch2 in product(font.keys(), repeat=2):
combined = [font[ch1][i] + font[ch2][i] for i in range(5)]
combined_stripped = [strip_spaces(line) for line in combined]
if combined_stripped == target_stripped:
matches.append(ch1 + ch2)
return matches
def normalize_target(target, line_length=6, total_lines=5):
padded_lines = [line.ljust(line_length) for line in target]
missing_lines = total_lines - len(padded_lines)
empty_line = " " * line_length
return [empty_line] * missing_lines + padded_lines
def main():
targets = [
['#### ', '## ', '### ', '## ', '######'],
['### ', '#### ', '##### ', '#### ', '#### '],
['### ', '# ', '### ', '## ', '### '],
[' ', '#### ', '### ', '##### ', ' '],
['### ', '# ', '# ', '# ', '#### '],
['## ', '##### ', '##### ', '#### ', '## '],
['## ', '######', '## ', '#### ', ' '],
['### ', '#### ', '### ', '## ', '### '],
[' ', '## ', '## ', '## ', '### '],
['## ', '##### ', '######', '### ', '# '],
['# ', '######', '## ', '##### ', ' '],
['## ', '##### ', '### ', '### ', '### '],
[' ', '##### ', '#### ', '#### ', '### '],
['## ', '## ', '### ', '# ', '#### '],
['# ', '### ', '# ', '## ', '### '],
['### ', '### ', '#### ', '## ', '##### '],
[' ', '##### ', '## ', '### ', ' '],
['### ', '# ', '# ', '# ', '#### '],
['# ', '##### ', '#### ', '######', ' '],
['### ', '# ', '# ', '# ', '#### '],
['## ', '######', '### ', '#### ', ' '],
['### ', '### ', '#### ', '### ', '### '],
[' ', '## ', '### ', '# ', '######'],
['### ', '#### ', '#### ', '##### ', '### '],
[' ', '## ', '## ', '## ', '### '],
['######', '## ', '#### ', '## ', '######'],
['# ', '### ', '## ', '### ', '### '],
['## ', '## ', '### ', '# ', '#### '],
['#### ', '#### ', '#### ', '### ', '### '],
[' ', '##### ', '### ', '#### ', ' '],
['# ', '#### ', '## ', '### ', '### '],
['## ', '##### ', '## ', '### ', '### '],
[' ', '### ', '# ', '### ', '### '],
['#### ', '##### ', '### ', '#### ', '### '],
[' ', '## ', '## ', '## ', '### '],
['## ', '##### ', '#### ', '## ', '# '],
['### ', '##### ', '### ', '### ', '### '],
[' ', '## ', '### ', '### ', '### '],
['## ', '##### ', '## ', '### ', '### '],
['# ', '### ', '## ', '### ', '### '],
['### ', '#### ', '##### ', '##### ', '### '],
['## ', '### ', '#### ', '### ', '## ']
]
skip = 0
for index, target in enumerate(targets[skip:]):
normalized_target = normalize_target(target)
matches = find_all_two_char_matches(normalized_target, FONT_5x3)
print(f"[{index + 1 + skip:02}] Matches found: {matches}")
flag = "L3 AK {j us 7_ p4 tt 3r n_ m4 tc h1 ng _4 t_ f1 rs 7_ bu 7_ th 3n _y 0u _n 33 d_ 4_ h3 ur 1s t1 c_ t0 _n 4r r0 w_ 1t _d 0w n}"
flag = flag.replace(" ", "")
target_hash = "a7bf5f833c3e4ceff2e006ff801ec16b"
md5_hash = hashlib.md5(flag.encode()).hexdigest()
if md5_hash == target_hash:
print(f"\nMD5 Match ! => {md5_hash}")
print(flag)
if __name__ == '__main__':
main()