
La Fuite de Données Personnelles par l'Informatique Fantôme (Shadow IT)
Introduction : Le mystère du PDF trop lourd
Dans le cadre de nos échanges numériques, il est fréquent de recevoir des correspondances officielles par courriel sous forme de fichiers PDF. Ces documents sont souvent porteurs de PII (Personally Identifiable Information), telles que des noms, adresses ou numéros de registre national.
Pour un praticien de l'OpSec (Sécurité Opérationnelle), la vigilance commence dès la réception du fichier par un geste simple : l’examen de son poids. Un document PDF composé uniquement de texte est structurellement léger. Le poids d'une page varie entre 10 et 50 kilooctets. Par conséquent, si un fichier de seulement quelques pages affiche une taille de plusieurs mégaoctets, cela doit immédiatement déclencher une alerte.
Le signal d'alarme
Cette disproportion est le signe révélateur que le document n'est pas ce qu'il prétend être. Il n'est pas composé de caractères, mais probablement d'images haute résolution ou de couches de données invisibles, augmentant ainsi drastiquement la surface de risque pour vos données personnelles.
Tout le monde devrait prendre les PII au sérieux. Les documents contenant des PII regroupent des informations permettant une usurpation d'identité en bonne et due forme (nom, adresse, n° de registre national, signatures, etc.).
Le smartphone : le maillon faible
Les scanners traditionnels sont devenus has-been face à l'avènement des smartphones et de leurs lentilles à haute résolution. Il est désormais extrêmement tentant de photographier un document pour le convertir instantanément en PDF.
Cependant, ce confort d'utilisation cache un piège technique. Le PDF ne contient plus du texte exploitable, mais devient un simple conteneur dans lequel sont encapsulées une (des) image(s) haute résolution. Ce changement de nature transforme le smartphone en un Point of Failure (point de défaillance) critique pour plusieurs raisons majeures:
- Contrairement à un scanner professionnel sécurisé au sein d'une organisation, le smartphone est souvent un appareil hybride (personnel/professionnel). Sa sécurité devrait idéalement être maîtrisée par un MDM (Mobile Device Management), mais ce n'est pas toujours le cas.
- Des logiciels espions comme Pegasus de NSO Group, exploitant des failles inconnues dites Zero-Day, peuvent prendre le contrôle total de l'appareil à distance. Une fois compromis, chaque document contenant des PII photographiés devient accessible à l'attaquant. De plus, la présence d'applications contenant des malwares n'est pas un cas exceptionnel.
- Un smartphone est mobile et donc vulnérable. Qu'il soit laissé déverrouillé sur un coin de table, perdu ou volé, la sécurité d'accès est souvent bien plus faible que celle d'un système d'information d'entreprise. Les photos de documents officiels stockées dans la galerie ou le cache des applications deviennent alors des proies faciles.
- Une photo ne capture pas que l'image du papier. Elle génère des métadonnées (EXIF) et conserve une résolution inutilement élevée. Cela crée un fichier anormalement lourd (plusieurs mégaoctets pour quelques pages) qui signale immédiatement une anomalie lors d'une analyse OpSec.
Traiter ou stocker des documents contenant des PII via un appareil non maîtrisé constitue non seulement un risque technique, mais possiblement un manquement sérieux au RGPD.
L'enquête forensique
Face à une telle situation, l'Ethical Hacker endosse sa casquette d'enquêteur forensique. Il doit impérativement obtenir des réponses aux questions suivantes (liste non exhaustive):
- Quel outil a été utilisé pour générer ce pdf ?
-
Cet outil a-t-il été approuvé par le Responsable Sécurité (RSI) de l'émetteur ?
-
L'émetteur du PDF dispose-t-il d'un accord de confidentialité (NDA) ou d'un contrat de traitement de données (DPA) avec l'éditeur de l'outil ?
-
Le RGPD est-il respecté ?
-
Si l'organisation émettrice est certifiée ISO 27001, cette pratique est-elle conforme à ses propres politiques de sécurité ?
Dans ce tutoriel, inspiré d'un cas réel que j'ai personnellement vécu, nous partons du postulat que nous avons reçu un courriel avec un PDF en attachement d'une entreprise basée en Europe et certifiée ISO27001. Ce fichier PDF après consultation révèlera qu'il contient des PII comme par exemple le numéro national. Comme donnée personnellement identifiable on peut difficilement faire mieux. Afin d'analyser s'il y a violation du RGPD et des normes ISO27001, nous réalisons une analyse forensique. Celle-ci détaille pas à pas les étapes d'une analyse d'un fichier PDF. Nous verrons comment extraire les métadonnées cachées pour confronter une 'correspondance officielle' à sa réalité technique. Certains diront ' Nothing2hide'. D'autres, dont je fais partie, considèrent qu'une telle violation de leurs droits ne peut rester sans réponse. L'objectif de ce tutoriel est de permettre à tout un chacun, selon son propre threat model, de définir sa stratégie de défense. Néanmoins, cet écrit se veut avant tout éducatif : nous nous concentrerons sur la méthodologie technique et de survoler le fond juridique.
Cas Pratique : Analyse Forensique du "PDF trop lourd"
Comme dit dans l'introduction, cet article est inspiré d'un fait qui m'est réellement arrivé. Je vais décrire l'analyse forensique que j'ai réalisée, quels outils utilisés, les constats et les enjeux. Bien sûr pour les besoins de cet article j'ai anonymisé les données sensibles, mais cela n'a pas d'incidence sur l'analyse.
1. Les outils utilisés pour l'enquête et leur version.
Une analyse forensique doit pouvoir être reproduite. Dans ce cas, les outils doivent être versionnés sans quoi les résultats pourraient être différents d'une reproduction à l'autre. La première étape est donc d'identifier le système d'exploitation : Ce sera Kali Linux version 2025.4. Ensuite chaque outil sera répertorié y compris sa version.
Pour cette analyse j'ai donc listé dans mon rapport les outils utilisés :
- cp (GNU coreutils) 9.7 - Packaged by Debian (9.7-3)
- sha256sum (GNU coreutils) 9.7 - Packaged by Debian (9.7-3)
- md5sum (GNU coreutils) 9.7 - Packaged by Debian (9.7-3)
- pdfinfo - The Poppler Developers (25.03.0)
- pdfimages - The Poppler Developers (25.03.0)
- exiftool - Phil Harvey (13.36)
2. La Phase de Collecte et l'Intégrité
Avant toute manipulation, ce n'est pas évident pour tout le monde mais on va travailler sur une copie. Cela pour respecter la '"Chain of Custody". Si le moindre bit du fichier original venait à être modifié, l'analyse forensique peut se révéler caduque et indéfendable.
Pour figer la preuve et d'être toujours en mesure de savoir si je travaille sur un fichier non modifié en cours d'analyse, nous allons extraire la signature cryptographique unique du fichier. Il y a nombre d'utilitaires capables de fournir la signature cryptographique. J'en utilise généralement deux : sha256sum et md5sum.
-
md5sum : Bien qu'il soit aujourd'hui considéré comme vulnérable aux collisions (deux fichiers différents pouvant techniquement produire la même signature), il reste extrêmement rapide et universellement utilisé. C'est un avantage non négligeable lors du traitement de fichiers volumineux.
-
sha256sum : Il apporte la sécurité et la certitude mathématique là où le MD5 pourrait faire défaut.
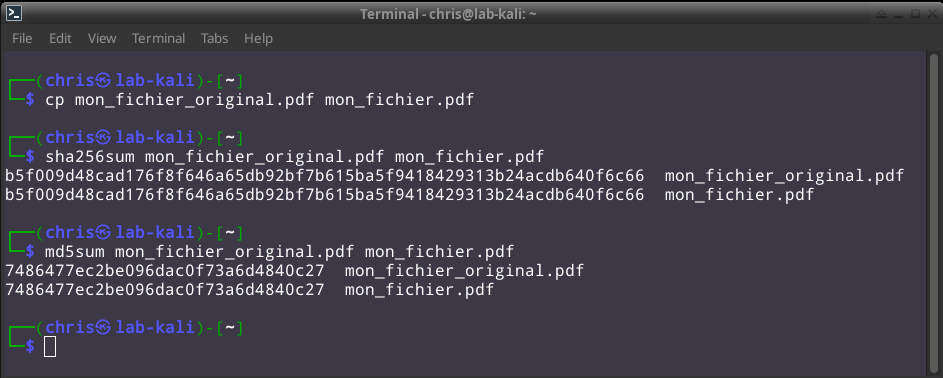
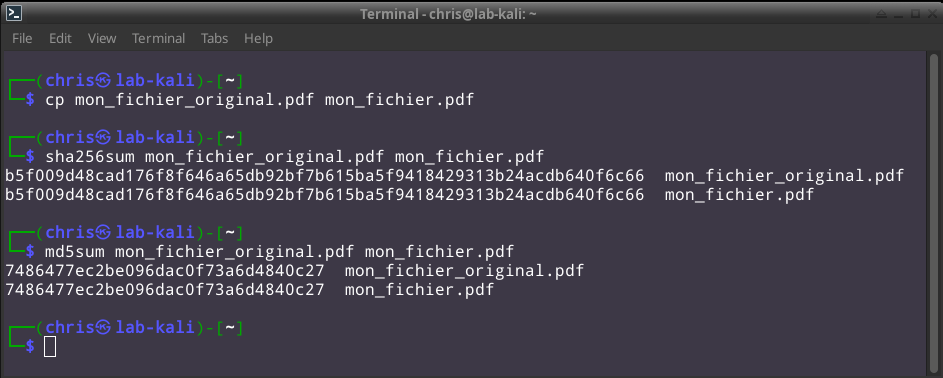
Comme illustré dans la capture d'écran ci-dessus, je crée une copie de travail de l'original. Pour respecter la 'Chain of Custody', je ne toucherai plus à l'original. Je vérifie ensuite que la copie est rigoureusement identique en comparant les signatures cryptographiques.
Je sauve dans mon rapport les deux signatures cryptographiques. Elles sont uniques au fichier.
SHA256 : b5f009d48cad176f8f646a65db92bf7b615ba5f9418429313b24acdb640f6c66
MD5 : 7486477ec2be096dac0f73a6d4840c27
3. Analyse des métadonnées du conteneur PDF
Une fois l'intégrité du fichier garantie, l'étape suivante consiste à consulter les métadonnées du conteneur PDF. Pour cela, nous utilisons l'outil pdfinfo
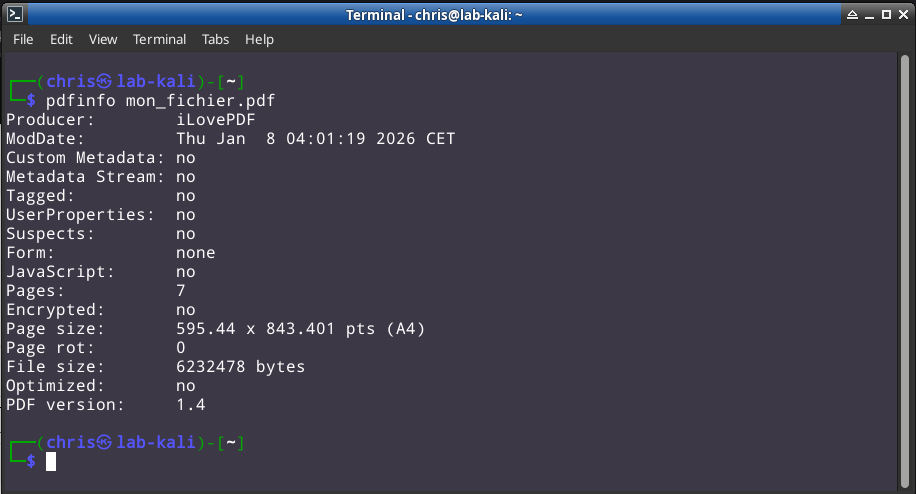
Cela révèle déjà des données que nous allons interpréter :
- Producer :
iLovePDF- L'outil qui a généré ce conteneur s'appelle iLovePDF. Une interrogation rapide sur un moteur de recherche révèle qu'il ne s'agit pas d'un utilitaire mais bien d'un service gratuit de génération de PDF.
- L'outil qui a généré ce conteneur s'appelle iLovePDF. Une interrogation rapide sur un moteur de recherche révèle qu'il ne s'agit pas d'un utilitaire mais bien d'un service gratuit de génération de PDF.
- ModDate : Thu Jan 8 04:01:19 2026 CET
- Le conteneur PDF a été généré le Jeudi 8 Janvier 2026 à 04h01m19s heure CET (Europe Centrale)
- C'est un peu le certificat de naissance du PDF
- Pages: 7
- Le nombre de pages que contient le PDF
- Page size: 595.44 x 843.401 pts (A4)
- Le format des pages est du A4
- File size: 6232478 bytes
- La taille du fichier est d'approximativement 6.23 Mo pour 7 pages.
- Ce qui ferait en moyenne ~890 Ko pour chaque page. C'est bien trop pour du texte.
- PDF version: 1.4
- La version du PDF. Il s'agit de la version 1.4. Sans rentrer dans les détails des versions PDF, ceci est plutôt une bonne nouvelle pour notre enquête mais c'est à contrario une moins bonne nouvelle d'un point de vue sécurité des données. La version 1.4 est très ancienne et a été introduite en 2001. Chaque image est un objet, ce qui facilitera grandement l'extraction des images que nous verrons plus loin. S'il s'agissait d'une version 1.7, les objets seraient compressés dans un seul gros bloc binaire. Les recherches et extractions resteraient possibles mais demanderaient plus de manipulations.
À la lecture des métadonnées, nous pouvons démontrer qu'un service cloud tiers a été utilisé. Cela implique que des données sensibles ont transité par des serveurs dont la localisation et la sécurité échappent au contrôle de l'émetteur, créant un point de friction majeur avec le RGPD.
Pour clarifier la situation, deux axes d'interrogation s'imposent : 1. Côté prestataire (iLovePDF dans ce tuto) : Interroger leur DPO - Délégué à la Protection des Données (ou Data Protection Officer en anglais) sur les garanties offertes par la plateforme. 2. Côté émetteur du document : Le RSI, Responsable de la Sécurité de l'Information a-t-il validé cet outil ? Existe-t-il un NDA, un accord de confidentialité (Non Disclosure Agreement) et/ou un DPA, contrat de traitement de données (Data Processing Agreement) avec cet éditeur ?
Si le DPO de l'entreprise émettrice ne peut fournir ces garanties, nous sommes face à du Shadow IT (Informatique Fantôme). Au-delà du risque de fuite de données, cela expose l'organisation à un dommage réputationnel grave auprès des autorités de contrôle (comme la CNIL en France ou l'APD en Belgique) et met en péril sa certification ISO 27001, si elle en dispose.
Précisons qu'une version gratuite ou payante d'un service cloud ne change rien à la garantie de conformité si aucun DPA (Data Processing Agreement) n'a été signé spécifiquement entre l'entreprise et l'éditeur.
Payant ou gratuit, un outil peut être du Shadow IT s'il n'est pas approuvé par le RSI.
Note : Nous pourrions nous arrêter ici car la démonstation est faite, mais pour l'aspect éducatif de ce tutoriel, nous allons pousser les investigations plus loin en extrayant les images du conteneur et analyser les métadonnées pour voir ce que l'on y trouve.
4. Analyse des métadonnées des objets contenus
Introduction
L'analyse des métadonnées du PDF nous a permis de remonter jusqu'à la source : un service Cloud tiers utilisé via ce qui semble être un smartphone. Cependant, pour un enquêteur forensique, ce n'est que la surface. Le fichier PDF fait office de conteneur. Comme mentionné précédemment, la version 1.4 du PDF ne compresse pas les objets de manière complexe, ce qui nous permet de 'dissequer' littéralement le fichier pour en extraire les images brutes sans perte de qualité.
L'objectif de cette étape est de récupérer les fichiers images originaux tels qu'ils ont été injectés dans le service iLovePDF et analyser les métadonnées. Nous allons passer du stade de la 'suspicion' à celui de la 'preuve matérielle' en dévoilant ce que l'émetteur n'imaginait probablement pas une seconde se trouvant dans le PDF qu'il aura généré : les métadonnées de l'appareil de capture.
Cartographie structurelle du conteneur PDF
Nous utilisons l’utilitaire pdfimages (de la suite poppler-utils, duquel pdfinfo est également issu). Cet outil est fondamental car il permet d'extraire le flux binaire original de chaque objet graphique, tel qu'il a été injecté dans le conteneur par le logiciel de création.
Avant de sortir ce qu'il y a dans le conteneur, nous allons d'abord ouvrir la porte et réaliser l'inventaire de ce qu'il contient. Pour cela on utilisera l'option -list de l'utilitaire pdfimages
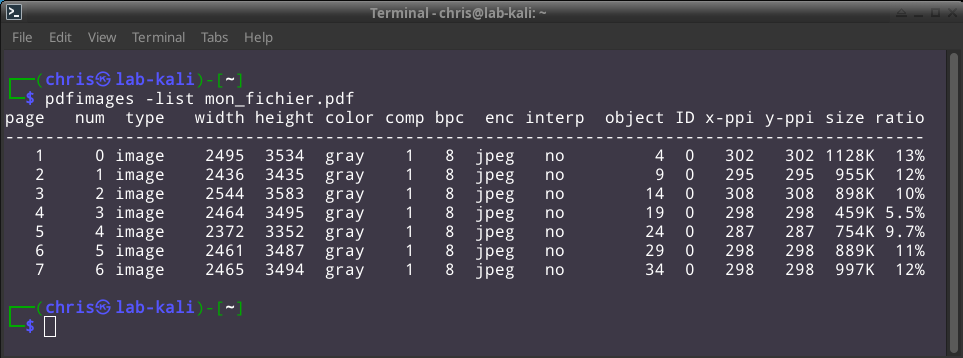
Décrivons les indicateurs techniques qui nous intéressent vraiment :
- page : Indique sur quelle page du PDF l'image a été trouvée
- num : Identifiant séquentiel de l'image (commençant par 0), qui servira notamment d'index pour nommer les fichiers lors de l'extraction
- type : type d'objet trouvé. "image" confirme qu'il s'agit d'un contenu visuel standard.
- width & height : Dimensions horizontale et verticale de l'image en pixels.
- À titre de comparaison, un scan A4 standard en 300 DPI affiche 2480 x 3508 px.
- La variabilité des valeurs trouvées dans le PDF analysé démontre un redimensionnement (manuel ou automatique) opéré sur chaque image avant l’assemblage sur la plateforme iLovePDF.
- enc (Encoding) : La valeur jpeg indique que les images sont stockées nativement dans ce format compressé. Ce qui peut être une bonne nouvelle pour nous puisque ce format de fichier graphique est très souvent porteur de métadonnées EXIF propre à l'appareil photo qui a généré l'image.
- size : taille apparente de l'image compressée (ex: 1128K pour la première). Cela donne une idée du poids des fichiers une fois extraits.
- x-ppi : Résolution horizontale (densité de pixels sur la largeur). PPI signifie Pixels Per Inch (Pixels Par Pouce). 1 pouce = 2.54cm.
- y-ppi : Résolution verticale (densité de pixels sur la hauteur). La signification de PPI est identique à x-ppi
- Sur un scanner professionnel, nous aurions obtenu une valeur fixe et standardisée (ex: 300 x 300 ou 600 x 600) pour chaque page. Ici, nous observons une variabilité constante : 302, 295, 308, 298, 287. Cette fluctuation prouve que chaque page a été capturée individuellement avec un recul ou un cadrage légèrement différent, ce qui est typique d'une prise de vue à main levée avec un smartphone.
Extraction physique des objets graphiques contenus dans le PDF
Nous avons ouvert le conteneur, nous avons réalisé son inventaire, nous pouvons maintenant sortir tous les cartons! Pour ce faire nous utiliserons de nouveau la commande pdfimages mais cette fois-ci avec l'option -all. Lorsque la commande pdfimages -all est lancée et se termine avec succès, elle n'affiche rien en retour. Pour cette raison je vais ajouter l'option -print-filenames qui aura au moins le mérite de fournir une sortie.
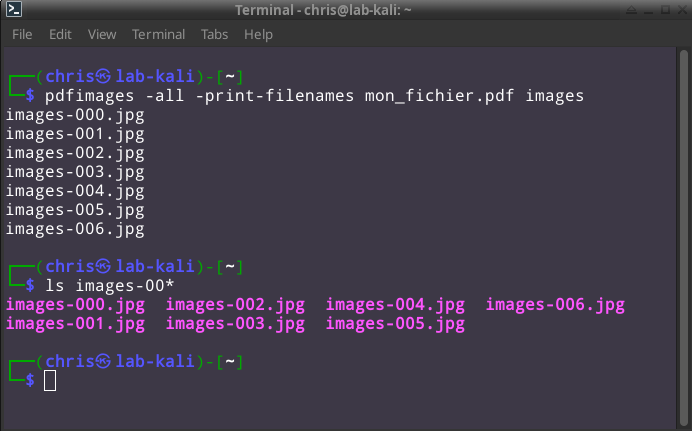
Ce ne sera pas abordé maintenant, mais chaque fichier .jpg extrait du conteneur PDF a son hachage.
Dans le rapport d'analyse forensique, j'ajouterais le hash SHA256 (sha256sum) et MD5 (md5sum) de chaque image extraite.
S'il faut prouver que le pdf n'a été en aucun cas altéré de l'original, il en sera de même avec les objets contenus dedans. Il est donc important de mentionner les hachages pour la préservation de la Chaine de preuves (Chain of Custody)
Ouverture des "cartons" et inspection douanière
Une fois les images extraites physiquement sur notre machine de travail, nous passons de l'analyse du contenant à celle du contenu. Pour rester dans notre analogie logistique, nous allons maintenant ouvrir un échantillon de cartons pour vérifier les "étiquettes de fabrication" invisibles à l'œil nu.
Pour réaliser cette tâche, l'outil de référence sera exiftool. Cet utilitaire permet de lire les métadonnées EXIF (Exchangeable Image File Format), qui sont de véritables empreintes numériques laissées par l'appareil de capture.
En tant que "douaniers", nous cherchons le premier point de contact. La première image est souvent celle qui définit le flux de travail de l'utilisateur. Si le premier carton est "contaminé" par des métadonnées, il est fort probable que l'ensemble de la cargaison le soit aussi.
J'utilise la commande exiftool -a -u -g1 images-000.jpg | grep -v "Profile Description ML" | grep ":". Les deux grep sont optionnels mais je les utilise car que je ne veux pas m'encombrer de traductions et de séparateurs inutiles. Je recherche un output court, complet et optimisé.
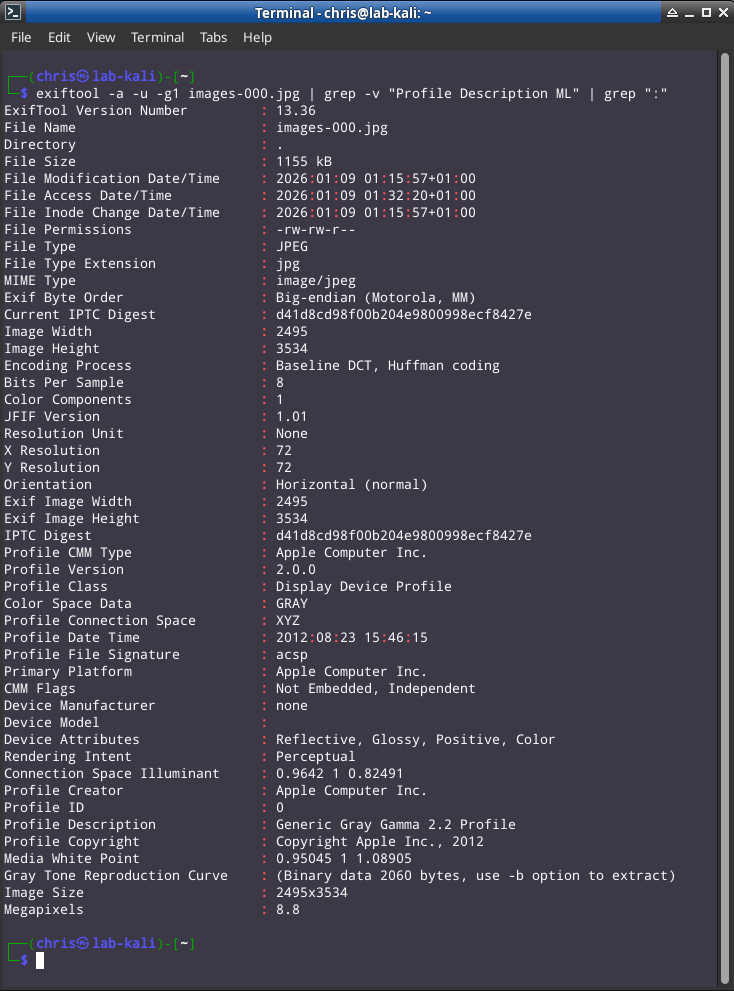
Nous recherchons une preuve de l'origine matérielle. En d'autres termes : Quel appareil a été utilisé pour générer l'image ?
En examinant les métadonnées de l'image images-000.jpg, nous isolons les éléments qui trahissent irrémédiablement le processus de création.
- Profile CMM Type, Primary Platform, Profile Creator, Profile Copyright : Ces indicateurs sont assez parlants. L'appareil utilisé pour créér et traiter l'image (le scan) est un appareil de l'écosystème Apple, ce qui relève d'une signature forte pour un iPhone, un iPAD ou un Mac. Bien qu'un Mac puisse techniquement générer ces profils (via la webcam ou un export spécifique), cette éventualité est extrêmement peu probable pour un "scan" de document de sept pages. L'ergonomie d'un MacBook ou d'un iMac ne se prête absolument pas à la prise de vue de documents papier, nous allons donc l'écarter. Les possibilités restantes sont iPhone et Ipad
-
Color Space Data, Profile Description : L'image originale capturée par un capteur photo est nativement en couleurs (RVB). La présence d'un profil GRAY prouve qu'un traitement logiciel a été appliqué pour transformer la photo en document "noir et blanc". C'est la signature typique des applications de "scan" mobile (comme l'outil Scan natif d'iOS ou Adobe Scan) qui tentent de donner un aspect professionnel à une simple photographie. La valeur du Gamma (2.2) indique que l'image a été optimisée pour être lisible sur un écran plutôt qu'être digitalisée fidèlement par un scanner professionnel. Ce passage en 2.2 écrase certaines nuances de l'image d'origine pour augmenter les contrastes. En d'autres termes, rendre le texte plus noir et le fond plus blanc, ce qui est typique des applications de scan.
- X Resolution, Y Resolution : Une résolution de 72 DPI est le standard de l'affichage web et écran, ce qui est totalement anormal pour un document scanné par un scanner professionnel. Dans ce cas les résolutions auraient été vers des standards de 300 à 600 dpi. Cette valeur est la signature d'un moteur de rendu mobile (iOS) qui a "aplati" la photo pour en réduire le poids tout en conservant une lisibilité écran. Cela confirme que l'image a été préparée pour une consommation numérique rapide, et non pour un archivage documentaire.
- Image Size : Une taille de 2495 x 3534 pixels démontre un redimensionnement de l'image pour s'approcher d'un format de papier A4 qui lui est de 2480 x 3508 pixels, tel que nous l'avons précédemment mentionné lors de l'analyse des métadonnées du PDF conteneur.
- Megapixels : une résolution d'image de 8.8 Mégapixels est inutile pour du texte, et explique le poids excessif du PDF. Elle prouve que nous manipulons une photographie haute définition qui a capturé bien plus que du texte (grain du papier, micro-ombres), augmentant inutilement la surface de données stockées, même après le post-traitement de l'appareil ou encore celui appliqué par iLovePDF.
Nous avons assez d'éléments technique à ajouter dans le rapport d'analyse forensique pour affirmer que le fichier PDF analysé contient bien des photos prises avec un appareil de l'écosystème Apple. iLovePDF a "nettoyé" certains éléments de l'EXIF, rendant impossible d'affirmer factuellement s'il s'agit d'un iPhone ou d'un iPad. Les tags temporels DateTimeOriginal ou CreateDate ont aussi été supprimés de l'EXIF. Il n'est donc pas possible à ce stade de dater précisément la prise de vue.
Examen visuel : Les stigmates de la capture manuelle
Au-delà des métadonnées, l'inspection visuelle des images révèleront des indices caractéristiques d'une manipulation non professionnelle. Dans un rapport forensique, ces éléments sont appelés des "artefacts de capture" qui confirmeront plutôt l'usage du smartphone ou d'une tablette qu'un scanner professionnel. Par exemple :
-
Défauts de géométrie et cadrage : Contrairement à un scanner à plat qui garantit un alignement parfait, on pourra observer des bords de page légèrement courbes ou des erreurs de parallaxe. Si la feuille n'est pas parfaitement plane, cela créera des distorsions dans le texte.
-
Les ombres et reflets : On distingue souvent des ombres portées causées par le smartphone lui-même ou par l'utilisateur se tenant entre la source de lumière et le document. On peut également noter des coins de feuille pliés ou la présence du support (table, bureau) sur les bords de l'image.
-
Bruit numérique et pixellisation : Malgré une résolution élevée (8.8 MP), un "zoom" avec une application graphique sur les caractères peut révéler une pixellisation et du bruit numérique dans les zones sombres. C'est dû au post-traitement logiciel (le fameux profil Gamma 2.2 dont on parlait précédemment) qui tente de compenser le manque de piqué de l'optique mobile par rapport à un capteur de numérisation industriel.
Pour illustrer le bruit numérique et la pixellisation, voici deux images :
|
Extrait d'un PDF généré par Libreoffice Writer |
Le même document généré par Libreoffice Writer imprimé sur papier, scanné avec un smartphone et téléversé sur iLovePDF pour convertir le jpeg en pdf. |

Conclusion : De la donnée brute au manquement de conformité
Au terme de cette analyse forensique, la réalité technique a fini par rattraper la "correspondance officielle". Ce que nous avons découvert dans les entrailles de ce fichier PDF n'est pas seulement un empilement de pixels, mais la preuve d'un flux de données complexe impliquant des terminaux mobiles et des services cloud tiers.
Le constat technique
Nous avons prouvé que ce document, émanant d'une entité certifiée ISO 27001, n'a pas suivi le flux de numérisation standard attendu. L'usage d'un appareil mobile Apple et du service iLovePDF a laissé des empreintes indélébiles. Toutefois, la technique seule ne suffit pas à qualifier cette pratique de Shadow IT.
L'enjeu pour le Threat Model
Pour lever l'ambiguïté et valider la conformité du traitement, une vérification s'impose auprès des DPO (Délégués à la Protection des Données) des deux parties :
-
-
Du côté de l'émetteur : le DPO doit être en mesure de produire la preuve matérielle (DPA et NDA signés) de la relation avec iLovePDF. Si ces documents font défaut ou ne couvrent pas spécifiquement cet usage, l'utilisation de l'outil bascule de facto dans le Shadow IT, rendant caduque toute promesse de conformité RGPD ou ISO 27001.
Du côté du prestataire (iLovePDF) : Le DPO doit pouvoir garantir la transparence du traitement : les données sont-elles stockées et/ou traitées hors Europe (risque lié au Cloud Act américain) ? Quelle est la durée de rétention ? Les fichiers sont-ils réellement supprimés après traitement ?
-
Il ne faut pas se contenter d'une réponse générique affirmant que 'tout est conforme' ou 'Nous accordons une importance primordiale à la protection des données...' En cas de doute persistant, seule une plainte auprès de l'autorité de la protection des données pourra de lever le voile, car elle seule peut exiger la consultation de ces documents confidentiels.
L'entreprise a-t-elle intérêt à en arriver là ? Absolument pas. Entre le risque de sanctions financières, l'atteinte à la réputation et la mise en péril d'une certification ISO 27001, le coût d'un 'mensonge' sur le Shadow IT dépasse largement celui d'une transparence honnête. La sécurité ne se décrète pas, elle se prouve.
Pour celui qui définit son threat model, cette investigation révèle que la confiance ne peut reposer uniquement sur une certification affichée sur un site web. La forensique permet de vérifier si les processus appliqués sur le terrain correspondent aux engagements de sécurité.
Si l'analyse forensique confirme que le traitement du document outrepasse les limites du threat model (modèle de menace), il reste la possibilité d'activer les leviers au niveau européen.
A. Le levier RGPD : Exercer son droit d'accès et d'information
Le RGPD offre à tout un chacun le pouvoir de demander des comptes. Si l'organisation ou son prestataire est incapable de répondre aux demandes de NDA/DPA, l'introduction d'une plainte ou un signalement auprès de l'autorité de protection des données (en Belgique, l'APD, la CNIL en France) est envisageable et même recommandée : c'est le seul levier concret pour transformer une conformité de façade en une réelle protection de nos données.
Les sanctions prévues par le RGPD (Règlement Général sur la Protection des Données) sont conçues pour être dissuasives, effectives et proportionnées. Dans le cas de notre tutoriel, si l'usage d'un outil tiers sans DPA/NDA est avéré, l'entreprise s'expose à plusieurs niveaux de réponse de la part des autorités de contrôle.
Cela peut aller de la mesure administrative comme l'avertissement ou le rappel à l'ordre jusqu'à des sanctions pécuniaires qui peuvent s'avérer très lourdes. Les amendes peuvent aller jusqu'à des sanctions pécuniaires qui peuvent s'avérer très lourdes. Les amendes s'élèvent jusqu'à 10 millions d'euros ou 2 % du chiffre d'affaires annuel mondial pour des manquements administratifs (comme l'absence de registre ou de contrat), et grimpent jusqu'à 20 millions d'euros ou 4 % pour des violations graves des droits des personnes.
En plus de l'amende versée à l'État, le RGPD (Article 82) prévoit que toute personne ayant subi un dommage (matériel ou moral) du fait d'une violation du règlement a le droit d'obtenir de la part du responsable du traitement réparation de son préjudice.
B. L'impact sur la certification ISO 27001
Bien que l'ISO 27001 soit une norme volontaire, une sanction RGPD aura un effet domino :
-
Un organisme de certification peut suspendre ou retirer le certificat si l'entreprise ne respecte plus les exigences légales (Contrôle A.18.1.1). Cependant il faut que l’auditeur juge que la non-conformité met en péril l’intégrité du SMSI (système de management de la sécurité de l'information). En d'autres termes, l'entreprise devra subir un audit complémentaire visant à lever la non-conformité majeure. Ce processus, bien plus intrusif et stressant qu'un audit de recertification planifié, force l'organisation à prouver en un temps record qu'elle a repris le contrôle sur son Shadow IT.
-
La révocation d'une certification ISO27001 peut se révéler un désastre en termes de réputation, souvent plus coûteux que l'amende elle-même.
Le mot de la fin
Certains persisteront à dire qu'ils n'ont "rien à cacher". Pourtant, cette analyse démontre que même un simple document administratif peut devenir un mouchard technique révélant les habitudes matérielles, logicielles et les failles organisationnelles d'un expéditeur.
La forensique n'est pas qu'une affaire de spécialistes ; c'est un outil d'émancipation pour tout citoyen numérique souhaitant confronter les promesses de sécurité à la réalité des faits. Encore faut-il savoir que faire, et comment. La prochaine fois que vous recevrez un PDF "trop lourd", n'oubliez pas : vous ne lisez pas seulement un message, vous avez la possibilité d'inspecter un conteneur qui a beaucoup de choses à vous dire. Protégez-vous en protégeant vos données, surtout les plus compromettantes, ne laissez rien passer!
Note de non-responsabilité (Disclaimer)
"Le présent tutoriel utilise le service iLovePDF à des fins purement illustratives et pédagogiques. L'utilisation de cet outil dans le cadre de cette analyse forensique ne constitue en aucun cas un jugement négatif sur la qualité, la fiabilité ou la sécurité intrinsèque du service.iLovePDF est un outil performant qui remplit parfaitement les fonctions pour lesquelles il a été conçu. Le risque mis en évidence dans cet article ne réside pas dans l'outil lui-même, mais dans l'usage qui en est fait par l'émetteur du document (Shadow IT). Il incombe à chaque organisation de s'assurer que l'utilisation de services tiers est conforme à sa propre politique de sécurité et aux exigences du RGPD (notamment via la signature d'un DPA). L'auteur ne saurait être tenu responsable d'une utilisation détournée des informations présentées dans ce cas pratique."
La Fuite de Données Personnelles par l'Informatique Fantôme (Shadow IT) © 2025 by Christian Vanguers is licensed under CC BY-NC 4.0. To view a copy of this license, visit https://creativecommons.org/licenses/by-nc/4.0/
My GPG Pubkey